\") in the corresponding marked box below.\n",
"\n",
"################\n",
"\n",
"Example input/output:\n",
"\n",
"################\n",
"\n",
"no_RDD_get_suggestions(\"there\")\n",
"\n",
"number of possible corrections: 604\n",
" edit distance for deletions: 3\n",
" \n",
"[('there', (2972, 0)),\n",
" ('these', (1231, 1)),\n",
" ('where', (977, 1)),\n",
" ('here', (691, 1)),\n",
" ('three', (584, 1)),\n",
" ('thee', (26, 1)),\n",
" ('chere', (9, 1)),\n",
" ('theme', (8, 1)),\n",
" ('the', (80030, 2)), ...\n",
"\n",
"####\n",
"\n",
"correct_document(\"OCRsample.txt\")\n",
"\n",
"Finding misspelled words in your document...\n",
" Unknown words (line number, word in text):\n",
"[(11, 'oonipiittee'), (42, 'senbrnrgs'), (82, 'ghmhvestigat')]\n",
" Words with suggested corrections (line number, word in text, top match):\n",
"[(3, 'taiths --> faith'), (13, 'gjpt --> get'), (13, 'tj --> to'), \n",
" (13, 'mnnff --> snuff'), (15, 'bh --> by'), (15, 'uth --> th'), ...\n",
" (15, 'unuer --> under'),\n",
"\n",
"---\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"\n",
"'''\n",
"\n",
"import findspark\n",
"import os\n",
"findspark.init('/Users/K-Lo/spark-1.5.0')\n",
"\n",
"from pyspark import SparkContext\n",
"sc = SparkContext()\n",
"\n",
"import re\n",
"\n",
"n_partitions = 6 # number of partitions to be used\n",
"max_edit_distance = 3\n",
"\n",
"# helper functions\n",
"def get_n_deletes_list(w, n):\n",
" '''given a word, derive list of strings with up to n characters deleted'''\n",
" # since this list is generally of the same magnitude as the number of \n",
" # characters in a word, it may not make sense to parallelize this\n",
" # so we use python to create the list\n",
" deletes = []\n",
" queue = [w]\n",
" for d in range(n):\n",
" temp_queue = []\n",
" for word in queue:\n",
" if len(word)>1:\n",
" for c in range(len(word)): # character index\n",
" word_minus_c = word[:c] + word[c+1:]\n",
" if word_minus_c not in deletes:\n",
" deletes.append(word_minus_c)\n",
" if word_minus_c not in temp_queue:\n",
" temp_queue.append(word_minus_c)\n",
" queue = temp_queue\n",
" \n",
" return deletes\n",
" \n",
"def copartitioned(RDD1, RDD2):\n",
" '''check if two RDDs are copartitioned'''\n",
" return RDD1.partitioner == RDD2.partitioner\n",
"\n",
"def combine_joined_lists(tup):\n",
" '''takes as input a tuple in the form (a, b) where each of a, b may be None (but not both) or a list\n",
" and returns a concatenated list of unique elements'''\n",
" concat_list = []\n",
" if tup[1] is None:\n",
" concat_list = tup[0]\n",
" elif tup[0] is None:\n",
" concat_list = tup[1]\n",
" else:\n",
" concat_list = tup[0] + tup[1]\n",
" \n",
" return list(set(concat_list))\n",
"\n",
"def parallel_create_dictionary(fname):\n",
" '''Create dictionary using Spark RDDs.'''\n",
" # we generate and count all words for the corpus,\n",
" # then add deletes to the dictionary\n",
" # this is a slightly different approach from the SymSpell algorithm\n",
" # that may be more appropriate for Spark processing\n",
" \n",
" print \"Creating dictionary...\" \n",
" \n",
" ############\n",
" #\n",
" # process corpus\n",
" #\n",
" ############\n",
" \n",
" # http://stackoverflow.com/questions/22520932/python-remove-all-non-alphabet-chars-from-string\n",
" regex = re.compile('[^a-z ]')\n",
"\n",
" # convert file into one long sequence of words\n",
" make_all_lower = sc.textFile(fname).map(lambda line: line.lower())\n",
" replace_nonalphs = make_all_lower.map(lambda line: regex.sub(' ', line))\n",
" all_words = replace_nonalphs.flatMap(lambda line: line.split())\n",
"\n",
" # create core corpus dictionary (i.e. only words appearing in file, no \"deletes\") and cache it\n",
" # output RDD of unique_words_with_count: [(word1, count1), (word2, count2), (word3, count3)...]\n",
" count_once = all_words.map(lambda word: (word, 1))\n",
" unique_words_with_count = count_once.reduceByKey(lambda a, b: a + b, numPartitions = n_partitions).cache()\n",
" \n",
" # output stats on core corpus\n",
" print \"total words processed: %i\" % unique_words_with_count.map(lambda (k, v): v).reduce(lambda a, b: a + b)\n",
" print \"total unique words in corpus: %i\" % unique_words_with_count.count()\n",
" \n",
" ############\n",
" #\n",
" # generate deletes list\n",
" #\n",
" ############\n",
" \n",
" # generate list of n-deletes from words in a corpus of the form: [(word1, count1), (word2, count2), ...]\n",
" \n",
" assert max_edit_distance>0 \n",
" \n",
" generate_deletes = unique_words_with_count.map(lambda (parent, count): \n",
" (parent, get_n_deletes_list(parent, max_edit_distance)))\n",
" expand_deletes = generate_deletes.flatMapValues(lambda x: x)\n",
" swap = expand_deletes.map(lambda (orig, delete): (delete, ([orig], 0)))\n",
" \n",
" ############\n",
" #\n",
" # combine delete elements with main dictionary\n",
" #\n",
" ############\n",
" \n",
" corpus = unique_words_with_count.mapValues(lambda count: ([], count))\n",
" combine = swap.union(corpus) # combine deletes with main dictionary, eliminate duplicates\n",
" \n",
" ## since the dictionary will only be a lookup table once created, we can\n",
" ## pass on as a Python dictionary rather than RDD by reducing locally and\n",
" ## avoiding an extra shuffle from reduceByKey\n",
" new_dict = combine.reduceByKeyLocally(lambda a, b: (a[0]+b[0], a[1]+b[1]))\n",
" \n",
" print \"total items in dictionary (corpus words and deletions): %i\" % len(new_dict)\n",
" print \" edit distance for deletions: %i\" % max_edit_distance\n",
" longest_word_length = unique_words_with_count.map(lambda (k, v): len(k)).reduce(max)\n",
" print \" length of longest word in corpus: %i\" % longest_word_length\n",
"\n",
" return new_dict, longest_word_length \n",
"\n",
"def dameraulevenshtein(seq1, seq2):\n",
" \"\"\"Calculate the Damerau-Levenshtein distance (an integer) between sequences.\n",
"\n",
" This code has not been modified from the original.\n",
" Source: http://mwh.geek.nz/2009/04/26/python-damerau-levenshtein-distance/\n",
" \n",
" This distance is the number of additions, deletions, substitutions,\n",
" and transpositions needed to transform the first sequence into the\n",
" second. Although generally used with strings, any sequences of\n",
" comparable objects will work.\n",
"\n",
" Transpositions are exchanges of *consecutive* characters; all other\n",
" operations are self-explanatory.\n",
"\n",
" This implementation is O(N*M) time and O(M) space, for N and M the\n",
" lengths of the two sequences.\n",
"\n",
" >>> dameraulevenshtein('ba', 'abc')\n",
" 2\n",
" >>> dameraulevenshtein('fee', 'deed')\n",
" 2\n",
"\n",
" It works with arbitrary sequences too:\n",
" >>> dameraulevenshtein('abcd', ['b', 'a', 'c', 'd', 'e'])\n",
" 2\n",
" \"\"\"\n",
" # codesnippet:D0DE4716-B6E6-4161-9219-2903BF8F547F\n",
" # Conceptually, this is based on a len(seq1) + 1 * len(seq2) + 1 matrix.\n",
" # However, only the current and two previous rows are needed at once,\n",
" # so we only store those.\n",
" oneago = None\n",
" thisrow = range(1, len(seq2) + 1) + [0]\n",
" for x in xrange(len(seq1)):\n",
" # Python lists wrap around for negative indices, so put the\n",
" # leftmost column at the *end* of the list. This matches with\n",
" # the zero-indexed strings and saves extra calculation.\n",
" twoago, oneago, thisrow = oneago, thisrow, [0] * len(seq2) + [x + 1]\n",
" for y in xrange(len(seq2)):\n",
" delcost = oneago[y] + 1\n",
" addcost = thisrow[y - 1] + 1\n",
" subcost = oneago[y - 1] + (seq1[x] != seq2[y])\n",
" thisrow[y] = min(delcost, addcost, subcost)\n",
" # This block deals with transpositions\n",
" if (x > 0 and y > 0 and seq1[x] == seq2[y - 1]\n",
" and seq1[x-1] == seq2[y] and seq1[x] != seq2[y]):\n",
" thisrow[y] = min(thisrow[y], twoago[y - 2] + 1)\n",
" return thisrow[len(seq2) - 1]\n",
"\n",
"def no_RDD_get_suggestions(s, masterdict, longest_word_length=float('inf'), silent=False):\n",
" '''return list of suggested corrections for potentially incorrectly spelled word.\n",
" \n",
" Note: serialized version for Spark document correction.\n",
" \n",
" s: input string\n",
" masterdict: the main dictionary (python dict), which includes deletes\n",
" entries, is in the form of: {word: ([suggested corrections], \n",
" frequency of word in corpus), ...}\n",
" longest_word_length: optional identifier of longest real word in masterdict\n",
" silent: verbose output (when False)\n",
" '''\n",
"\n",
" if (len(s) - longest_word_length) > max_edit_distance:\n",
" if not silent:\n",
" print \"no items in dictionary within maximum edit distance\"\n",
" return []\n",
"\n",
" ##########\n",
" #\n",
" # initialize suggestions list\n",
" # suggestList entries: (word, (frequency of word in corpus, edit distance))\n",
" #\n",
" ##########\n",
" \n",
" if not silent:\n",
" print \"looking up suggestions based on input word...\"\n",
" \n",
" suggestList = []\n",
" \n",
" # check if input word is in dictionary, and is a word from the corpus (edit distance = 0)\n",
" # if so, add input word itself and suggestions to suggestRDD\n",
" \n",
" if s in masterdict:\n",
" init_sugg = []\n",
" # dictionary values are in the form of ([suggestions], freq)\n",
" if masterdict[s][1]>0: # frequency>0 -> real corpus word\n",
" init_sugg = [(str(s), (masterdict[s][1], 0))]\n",
"\n",
" # the suggested corrections for the item in dictionary (whether or not\n",
" # the input string s itself is a valid word or merely a delete) can be \n",
" # valid corrections -- essentially we serialize this portion since\n",
" # the list of corrections tends to be very short\n",
" \n",
" add_sugg = [(str(sugg), (masterdict[sugg][1], len(sugg)-len(s))) \n",
" for sugg in masterdict[s][0]]\n",
" \n",
" suggestList = init_sugg + add_sugg\n",
" \n",
" ##########\n",
" #\n",
" # process deletes on the input string \n",
" #\n",
" ##########\n",
" \n",
" assert max_edit_distance>0\n",
" \n",
" list_deletes_of_s = get_n_deletes_list(s, max_edit_distance) # this list is short\n",
" \n",
" # check suggestions is in dictionary and is a real word\n",
" add_sugg_2 = [(str(sugg), (masterdict[sugg][1], len(s)-len(sugg))) \n",
" for sugg in list_deletes_of_s if ((sugg in masterdict) and\n",
" (masterdict[sugg][1]>0))]\n",
" \n",
" suggestList += add_sugg_2\n",
" \n",
" # check each item of suggestion list of all new-found suggestions \n",
" # the suggested corrections for any item in dictionary (whether or not\n",
" # the delete itself is a valid word or merely a delete) can be valid corrections \n",
" # expand lists of list\n",
" \n",
" sugg_lists = [masterdict[sugg][0] for sugg in list_deletes_of_s if sugg in masterdict]\n",
" list_sl = [(val, 0) for sublist in sugg_lists for val in sublist]\n",
" combine_del = list(set((list_sl))) \n",
"\n",
" # need to recalculate actual Deverau Levenshtein distance to be within \n",
" # max_edit_distance for all deletes; also check that suggestion is a real word\n",
" filter_by_dist = []\n",
" for item in combine_del:\n",
" calc_dist = dameraulevenshtein(s, item[0])\n",
" if (calc_dist<=max_edit_distance) and (item[0] in masterdict):\n",
" filter_by_dist += [(item[0], calc_dist)]\n",
" \n",
" # get frequencies from main dictionary and add new suggestions to suggestions list\n",
" suggestList += [(str(item[0]), (masterdict[item[0]][1], item[1]))\n",
" for item in filter_by_dist]\n",
" \n",
" output = list(set(suggestList))\n",
" \n",
" if not silent:\n",
" print \"number of possible corrections: %i\" % len(output)\n",
" print \" edit distance for deletions: %i\" % max_edit_distance\n",
"\n",
" ##########\n",
" #\n",
" # optionally, sort RDD for output\n",
" #\n",
" ##########\n",
" \n",
" # output option 1\n",
" # sort results by ascending order of edit distance and descending order of frequency\n",
" # and return list of suggested corrections only:\n",
" # return sorted(output, key = lambda x: (suggest_dict[x][1], -suggest_dict[x][0]))\n",
"\n",
" # output option 2\n",
" # return list of suggestions with (correction, (frequency in corpus, edit distance)):\n",
" # return sorted(output, key = lambda (term, (freq, dist)): (dist, -freq))\n",
"\n",
" if len(output)>0:\n",
" return sorted(output, key = lambda (term, (freq, dist)): (dist, -freq))\n",
" else:\n",
" return []\n",
" \n",
"def correct_document(fname, d, lwl=float('inf'), printlist=True):\n",
" '''Correct an entire document using word-level correction.\n",
" \n",
" Note: Uses a serialized version of an individual word checker. \n",
" \n",
" fname: filename\n",
" d: the main dictionary (python dict), which includes deletes\n",
" entries, is in the form of: {word: ([suggested corrections], \n",
" frequency of word in corpus), ...}\n",
" lwl: optional identifier of longest real word in masterdict\n",
" printlist: identify unknown words and words with error (default is True)\n",
" '''\n",
" \n",
" # broadcast lookup dictionary to workers\n",
" bd = sc.broadcast(d)\n",
" \n",
" print \"Finding misspelled words in your document...\" \n",
" \n",
" # http://stackoverflow.com/questions/22520932/python-remove-all-non-alphabet-chars-from-string\n",
" regex = re.compile('[^a-z ]')\n",
"\n",
" # convert file into one long sequence of words with the line index for reference\n",
" make_all_lower = sc.textFile(fname).map(lambda line: line.lower()).zipWithIndex()\n",
" replace_nonalphs = make_all_lower.map(lambda (line, index): (regex.sub(' ', line), index))\n",
" flattened = replace_nonalphs.map(lambda (line, index): \n",
" [(i, index) for i in line.split()]).flatMap(list)\n",
" \n",
" # create RDD with (each word in document, corresponding line index) \n",
" # key value pairs and cache it\n",
" all_words = flattened.partitionBy(n_partitions).cache()\n",
" \n",
" # check all words in parallel -- stores whole list of suggestions for each word\n",
" get_corrections = all_words.map(lambda (w, index): \n",
" (w, (no_RDD_get_suggestions(w, bd.value, lwl, True), index)),\n",
" preservesPartitioning=True).cache()\n",
" \n",
" # UNKNOWN words are words where the suggestion list is empty\n",
" unknown_words = get_corrections.filter(lambda (w, (sl, index)): len(sl)==0)\n",
" if printlist:\n",
" print \" Unknown words (line number, word in text):\"\n",
" print unknown_words.map(lambda (w, (sl, index)): (index, str(w))).sortByKey().collect()\n",
" \n",
" # ERROR words are words where the word does not match the first tuple's word (top match)\n",
" error_words = get_corrections.filter(lambda (w, (sl, index)): len(sl)>0 and w!=sl[0][0]) \n",
" if printlist:\n",
" print \" Words with suggested corrections (line number, word in text, top match):\"\n",
" print error_words.map(lambda (w, (sl, index)): \n",
" (index, str(w) + \" --> \" +\n",
" str(sl[0][0]))).sortByKey().collect()\n",
" \n",
" gc = sc.accumulator(0)\n",
" get_corrections.foreach(lambda x: gc.add(1))\n",
" uc = sc.accumulator(0)\n",
" unknown_words.foreach(lambda x: uc.add(1))\n",
" ew = sc.accumulator(0)\n",
" error_words.foreach(lambda x: ew.add(1))\n",
" \n",
" print \"-----\"\n",
" print \"total words checked: %i\" % gc.value\n",
" print \"total unknown words: %i\" % uc.value\n",
" print \"total potential errors found: %i\" % ew.value\n",
"\n",
" return"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" Run the cell below only once to build the dictionary.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"%%time\n",
"d, lwl = parallel_create_dictionary(\"testdata/big.txt\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 10.9 s, sys: 976 ms, total: 11.8 s\n",
"Wall time: 41.2 s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" Enter word to correct below.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"%%time\n",
"no_RDD_get_suggestions(\"theref\", d, lwl)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"looking up suggestions based on input word...\n",
"number of possible corrections: 604\n",
" edit distance for deletions: 3\n",
"CPU times: user 56.3 ms, sys: 4.17 ms, total: 60.5 ms\n",
"Wall time: 58.2 ms\n",
"Out[3]:\n",
"[('there', (2972, 0)),\n",
" ('these', (1231, 1)),\n",
" ('where', (977, 1)),\n",
" ('here', (691, 1)),\n",
" ('three', (584, 1)),\n",
" ('thee', (26, 1)),\n",
" ('chere', (9, 1)),\n",
" ('theme', (8, 1)),\n",
" ('the', (80030, 2)), ...\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"%%time\n",
"no_RDD_get_suggestions(\"zzffttt\", d, lwl)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"looking up suggestions based on input word...\n",
"number of possible corrections: 0\n",
" edit distance for deletions: 3\n",
"CPU times: user 419 µs, sys: 108 µs, total: 527 µs\n",
"Wall time: 435 µs\n",
"Out[3]:\n",
"[]\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" Enter file name of document to correct below.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"%%time\n",
"correct_document(\"testdata/OCRsample.txt\", d, lwl)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Finding misspelled words in your document...\n",
" Unknown words (line number, word in text):\n",
"[(11, 'oonipiittee'), (42, 'senbrnrgs'), (82, 'ghmhvestigat')]\n",
" Words with suggested corrections (line number, word in text, top match):\n",
"[(3, 'taiths --> faith'), (13, 'gjpt --> get'), (13, 'tj --> to'), (13, 'mnnff --> snuff'), (15, 'bh --> by'), (15, 'uth --> th'), (15, 'unuer --> under'), (15, 'snc --> sac'), (20, 'mthiitt --> thirty'), (21, 'cas --> was'), (22, 'pythian --> scythian'), (26, 'brainin --> brain'), (27, 'jfl --> of'), (28, 'eug --> dug'), (28, 'stice --> stick'), (28, 'blaci --> black'), (28, 'ji --> i'), (28, 'debbs --> debts'), (29, 'nericans --> americans'), (30, 'ergs --> eggs'), (30, 'ainin --> again'), (31, 'trumped --> trumpet'), (32, 'erican --> american'), (33, 'thg --> the'), (33, 'nenance --> penance'), (33, 'unorthodox --> orthodox'), (34, 'rgs --> rags'), (34, 'sln --> son'), (38, 'eu --> e'), (38, 'williaij --> william'), (40, 'fcsf --> ff'), (40, 'ber --> be'), (42, 'thpt --> that'), (42, 'unorthodoxy --> orthodox'), (44, 'fascism --> fascia'), (62, 'loo --> look'), (65, 'ththn --> then'), (65, 'thl --> the'), (65, 'yktcn --> skin'), (65, 'scbell --> bell'), (65, 'ife --> if'), (66, 'thi --> the'), (68, 'saij --> said'), (69, 'cornr --> corner'), (69, 'defendants --> defendant'), (69, 'nists --> lists'), (72, 'ro --> to'), (74, 'ath --> at'), (75, 'rg --> re'), (75, 'acrific --> pacific'), (75, 'tti --> tit'), (77, 'korea --> more'), (78, 'doatli --> death'), (78, 'ro --> to'), (81, 'ry --> by'), (81, 'ith --> it'), (81, 'kl --> ll'), (81, 'ech --> each'), (82, 'rg --> re'), (82, 'rb --> re'), (82, 'nb --> no'), (83, 'rosenbt --> rodent'), (83, 'rgs --> rags'), (84, 'coriritted --> committed'), (86, 'fighti --> fight'), (88, 'bths --> baths'), (88, 'tchf --> the'), (91, 'ro --> to'), (91, 'ijb --> in'), (92, 'telegrnm --> telegram'), (92, 'rson --> son'), (92, 'jillia --> william'), (92, 'patt --> part'), (93, 'ecretdry --> secretary'), (95, 'purview --> purves'), (95, 'rder --> order'), (99, 'gor --> for'), (99, 'rg --> re'), (99, 'enb --> end'), (99, 'dthethg --> teeth'), (99, 'ro --> to'), (99, 'ared --> are'), (100, 'dri --> dry'), (100, 'yfu --> you'), (100, 'vthnz --> the'), (100, 'sacc --> sac'), (101, 'rosi --> rose'), (101, 'rg --> re'), (101, 'ile --> ill'), (102, 'jhy --> why'), (102, 'fnir --> fair'), (102, 'azi --> ai'), (103, 'fascist --> fascia'), (104, 'nb --> no')]\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"CPU times: user 9.9 s, sys: 619 ms, total: 10.5 s\n",
"Wall time: 1min 3s\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"%%time\n",
"correct_document(\"testdata/OCRsample.txt\", d, lwl, False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"CPU times: user 9.33 s, sys: 505 ms, total: 9.83 s\n",
"Wall time: 56.3 s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"# additional tests (local machine)\n",
"\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 12029\n",
"total unknown words: 19\n",
"total potential errors found: 719\n",
"-----\n",
"266.66 seconds to run\n",
"-----\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 131340\n",
"total unknown words: 325\n",
"total potential errors found: 8460\n",
"-----\n",
"2897.28 seconds to run\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# AWS Experiments"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"It took a long time to debug problems with AWS, but in the end the programs ran. The key thing I learned is that when broadcasting the dictionary to the workers, we have to set the executor memory (e.g. to 5G or 8G) explicitly to ensure that the workers can store it (was originally left out). We also include sample output for the document-level Spark version below.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## individual word checks"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"# 2 executors, 4 cores, 16 partitions\n",
"# \"there\"\n",
"\n",
"serial: 62 ms\n",
"spark 1: 96.31 s\n",
"spark 2: 22.62 s\n",
"spark 3: 41.35 s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"This result was interesting, as the `reduceByKeyLocally` performs much worse with many workers. This is the reverse results compared to those obtained when running the Spark versions 2 and 3 on my local machine. The cost of a potential shuffle between building the dictionary and the word check seems negligble now, compared to the overhead of setting up communication with all the workers and then having to bring everything back to the driver.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## document checks (on AWS)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"# Serial version:\n",
"\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"-----\n",
"19.01 seconds to run\n",
"-----\n",
"\n",
"total words checked: 12029\n",
"total unknown words: 19\n",
"total potential errors found: 719\n",
"-----\n",
"384.75 seconds to run\n",
"-----\n",
"\n",
"-----\n",
"total words checked: 131340\n",
"total unknown words: 325\n",
"total potential errors found: 8460\n",
"-----\n",
"4305.46 seconds to run\n",
"-----\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"The serial version now lags behind the Spark versions once the documents size starts getting very big.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2 executors, 4 cores, 16 partitions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Please wait...\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"-----\n",
"35.37 seconds to run\n",
"-----\n",
" \n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"-----\n",
"41.82 seconds to run\n",
"-----\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"total words checked: 12029\n",
"total unknown words: 19\n",
"total potential errors found: 719\n",
"-----\n",
"125.45 seconds to run\n",
"-----\n",
"\n",
"-----\n",
"total words checked: 131340\n",
"total unknown words: 325\n",
"total potential errors found: 8460\n",
"-----\n",
"995.66 seconds to run\n",
"-----\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"The Spark versions begin to show their strength at the document sizes get larger. We began to fiddle with the various parameters (e.g. number of executors, number of cores, number of partitions set in the code). Note that we are still generating all suggestions for EACH words - for the purposes of comparing performance this is fine, but we would likely have to optimize the code (in the manner of the final serial version where we can terminate searches early once suggestions of the lowest edit distances are found) if we were to run this on even larger documents.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2 executors, 4 cores, 32 partitions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Please wait...\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"-----\n",
"34.84 seconds to run\n",
"-----\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"-----\n",
"66.17 seconds to run\n",
"\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 12029\n",
"total unknown words: 19\n",
"total potential errors found: 719\n",
"-----\n",
"150.06 seconds to run\n",
"-----\n",
"\n",
"*** when I left memory at 5G\n",
"-----\n",
"total words checked: 131340\n",
"total unknown words: 325\n",
"total potential errors found: 8460\n",
"-----\n",
"2357.24 seconds to run\n",
"-----\n",
"\n",
"*** boosted memory to 8G\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 131340\n",
"total unknown words: 325\n",
"total potential errors found: 8460\n",
"-----\n",
"972.82 seconds to run\n",
"-----\n",
"\n",
"*** changed reduceByKeyLocally to reduceByKey + collectAsMap in createDocument\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 131340\n",
"total unknown words: 325\n",
"total potential errors found: 8460\n",
"-----\n",
"992.03 seconds to run\n",
"-----\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4 executors, 4 cores, 16 partitions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"Please wait...\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"-----\n",
"66.97 seconds to run\n",
"-----\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"-----\n",
"148.86 seconds to run\n",
"-----\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 12029\n",
"total unknown words: 19\n",
"total potential errors found: 719\n",
"-----\n",
"240.04 seconds to run\n",
"-----\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4 executors, 4 cores, 32 partitions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Please wait...\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"-----\n",
"71.95 seconds to run\n",
"-----\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"-----\n",
"163.45 seconds to run\n",
"\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 12029\n",
"total unknown words: 19\n",
"total potential errors found: 719\n",
"-----\n",
"246.38 seconds to run\n",
"-----\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 131340\n",
"total unknown words: 325\n",
"total potential errors found: 8460\n",
"-----\n",
"1191.01 seconds to run\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4 executors, 4 cores, 64 partitions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"Please wait...\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"-----\n",
"69.25 seconds to run\n",
"-----\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"-----\n",
"198.92 seconds to run\n",
"-----\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 12029\n",
"total unknown words: 19\n",
"total potential errors found: 719\n",
"-----\n",
"286.15 seconds to run\n",
"\n",
"Document correction... Please wait...\n",
"-------------------------------------\n",
"finding corrections for document\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 131340\n",
"total unknown words: 325\n",
"total potential errors found: 8460\n",
"-----\n",
"1283.60 seconds to run\n",
"-----\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Future investigations may entail exploring and tuning these parameters, and experimenting with others, to optimize performance."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Appendix"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
In this section, we document various attempts at optimizing the original Spark (v 1.0) program. \n",
" Note we also examined the output at localhost:4040 to identify the time-consuming stages.\n",
"
\n",
"
Removed setting of executor memory decreased time to build dictionary. \n",
" Replace:\n",
"
\n",
"import pyspark\n",
"conf = (pyspark.SparkConf()\n",
" .setMaster('local')\n",
" .setAppName('pyspark')\n",
" .set(\"spark.executor.memory\", \"2g\"))\n",
"sc = pyspark.SparkContext(conf=conf)\n",
"
\n",
" with:\n",
"
\n",
" from pyspark import SparkContext\n",
" sc = SparkContext()\n",
"
\n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 113 ms, sys: 24.6 ms, total: 138 ms\n",
"Wall time: 2min 48s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Setting `minPartitions` argument in `textFile` did not improve performance. \n",
" Replace:\n",
"
\n",
"make_all_lower = sc.textFile(fname).map(lambda line: line.lower())\n",
"
\n",
" with:\n",
"
\n",
"make_all_lower = sc.textFile(fname, minPartitions = n_partitions).map(lambda line: line.lower())\n",
"
\n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 133 ms, sys: 28.9 ms, total: 162 ms\n",
"Wall time: 2min 55s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Repartitioning and sorting corpus after processing core words did not improve performance. \n",
" Replace:\n",
"
\n",
"unique_words_with_count = count_once.reduceByKey(lambda a, b: a + b, numPartitions = n_partitions).cache()\n",
"
\n",
" with:\n",
"
\n",
"unique_words_with_count = count_once.reduceByKey(lambda a, b: a + b).repartitionAndSortWithinPartitions(numPartitions =n_partitions).cache()\n",
"
\n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 150 ms, sys: 31.8 ms, total: 182 ms\n",
"Wall time: 3min 5s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Explicitly setting use_unicode to False, which is documented as possibly leading to a faster read, did not significantly improve performance. \n",
" Replace:\n",
"
\n",
"make_all_lower = sc.textFile(fname).map(lambda line: line.lower())\n",
"
\n",
" with:\n",
"
\n",
"make_all_lower = sc.textFile(fname, use_unicode=False).map(lambda line: line.lower())\n",
"
\n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 106 ms, sys: 24.3 ms, total: 130 ms\n",
"Wall time: 2min 46s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Removing parallelism when generating individual 1-deletes, 2-deletes, and 3-deletes improved performance. This is likely due to the fact that these lists are pretty short relative to the length of the corpus; parallelizing them introduces overhead.
\n",
" Replaced `get_deletes_list` with `get_n_deletes_list` function, and modified `parallel_create_dictionary` accordingly.
See Spark v. 2.0 above. \n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 52 ms, sys: 13 ms, total: 65 ms\n",
"Wall time: 54.1 s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Replacing a `join` with `union`, and `reduceByKey` with `reduceByKeyLocally` to return dictionary to driver without an extra shuffle, provides comparable performance (however, dictionary is now a python dictionary, and not an RDD).
\n",
" Modified `parallel_create_dictionary` accordingly.
See Spark v. 3.0 above. \n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 10.9 s, sys: 1.01 s, total: 11.9 s\n",
"Wall time: 42.1 s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Replacing `reduceByKeyLocally` with a `reduceByKey` and `collectAsMap` did not significantly improve performance. This is because an extra shuffle was introduced.
\n",
" Replace:\n",
"
\n",
"new_dict = combine.reduceByKeyLocally(lambda a, b: (a[0]+b[0], a[1]+b[1]))\n",
"
\n",
" with:\n",
"
\n",
"new_dict = combine.reduceByKey(lambda a, b: (a[0]+b[0], a[1]+b[1])).collectAsMap()\n",
"
\n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 7.16 s, sys: 921 ms, total: 8.08 s\n",
"Wall time: 1min 7s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Modifying the initial `reduceByKey` when reading the corpus to remove explicit partitioning (now not needed with the use of `union`) did not significantly improve performance. \n",
" Replace:\n",
"
\n",
"unique_words_with_count = count_once.reduceByKey(lambda a, b: a + b, numPartitions=n_partitions).cache()\n",
"
\n",
" with:\n",
"
\n",
"unique_words_with_count = count_once.reduceByKey(lambda a, b: a + b).cache()\n",
"
\n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 9.05 s, sys: 824 ms, total: 9.87 s\n",
"Wall time: 43.4 s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Increasing number of partitions from 6 to 8, on our local machine (dual core, 2015 MacBook Pro) did not significantly improve performance. \n",
" Replace:\n",
"
\n",
"n_partitions = 6 # number of partitions to be used\n",
"
\n",
" with:\n",
"
\n",
"n_partitions = 8 # number of partitions to be used\n",
"
\n",
"
\n",
"Creating dictionary...\n",
"total words processed: 1105285\n",
"total unique words in corpus: 29157\n",
"total items in dictionary (corpus words and deletions): 2151998\n",
" edit distance for deletions: 3\n",
" length of longest word in corpus: 18\n",
"CPU times: user 11.6 s, sys: 1.08 s, total: 12.7 s\n",
"Wall time: 45.5 s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### implement document checking"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Serializing `get_suggestions` allowed us to parallelize the checking of words within an entire document. Spark does not appear to permit parallelizing a task within a parallel task (transformation).
\n",
" Replaced `get_suggestions` with `no_RDD_get_suggestions` function, and modified `correct_document` accordingly. \n",
"
\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"CPU times: user 1min 6s, sys: 1.36 s, total: 1min 8s\n",
"Wall time: 2min 1s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Broadcasting dictionary to workers before checking document improved performance. \n",
" Added:\n",
"
\n",
" # broadcast lookup dictionary to workers\n",
" bd = sc.broadcast(d)\n",
"
\n",
" Modified `get_corrections` to:\n",
"
\n",
" get_corrections = all_words.map(lambda (w, index): (w, (get_suggestions(w, bd.value, lwl, True), index)), preservesPartitioning=True).cache()\n",
"
\n",
"
\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"CPU times: user 10.6 s, sys: 620 ms, total: 11.2 s\n",
"Wall time: 57.3 s\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Converting counters for words in dictionary, unknown words, and error words to accumulators only improved performance nominally (may not be significant due to variations between runs). These changes have been implemented. See Spark v. 4.0 above.
\n",
" Add:\n",
"
\n",
" gc = sc.accumulator(0)\n",
" get_corrections.foreach(lambda x: gc.add(1))\n",
" uc = sc.accumulator(0)\n",
" unknown_words.foreach(lambda x: uc.add(1))\n",
" ew = sc.accumulator(0)\n",
" error_words.foreach(lambda x: ew.add(1))\n",
"
\n",
" Modified print statements to read:\n",
"
\n",
" print \"total words checked: %i\" % gc.value\n",
" print \"total unknown words: %i\" % uc.value\n",
" print \"total potential errors found: %i\" % ew.value\n",
"
\n",
"
\n",
"Finding misspelled words in your document...\n",
"-----\n",
"total words checked: 700\n",
"total unknown words: 3\n",
"total potential errors found: 94\n",
"CPU times: user 9.33 s, sys: 505 ms, total: 9.83 s\n",
"Wall time: 56.3 s \n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
We tried using the MultiProcessing (Pool) module in Python in conjunction\n",
" with our Spark commands for the get_suggestions method. Unfortunately, this did not\n",
" seem to work, and the output gave errors causing system instability. Occasionally, it would give key errors, while at other times, it would give an error of the type: \"PythonRDD does not exist in the JVM\". This instability seems to be documented: http://stackoverflow.com/questions/32443362/passing-sparkcontext-to-new-process-python-multiprocessing-module. In any event, this is something that might be subject to further investigation in the future.
\n",
" Added:\n",
"
\n",
" def f(x):\n",
" val, dictionary, longestword, silent = x\n",
" return get_suggestions(val, dictionary, longestword, silent)\n",
"
\n",
" and to `create_dictionary`:\n",
"
\n",
" # parallelization via Pool\n",
" jobs = [(w, bd.value, lwl, False) for w in doc_words]\n",
" suggestion_lists = p.map(f, jobs)\n",
"
\n",
"
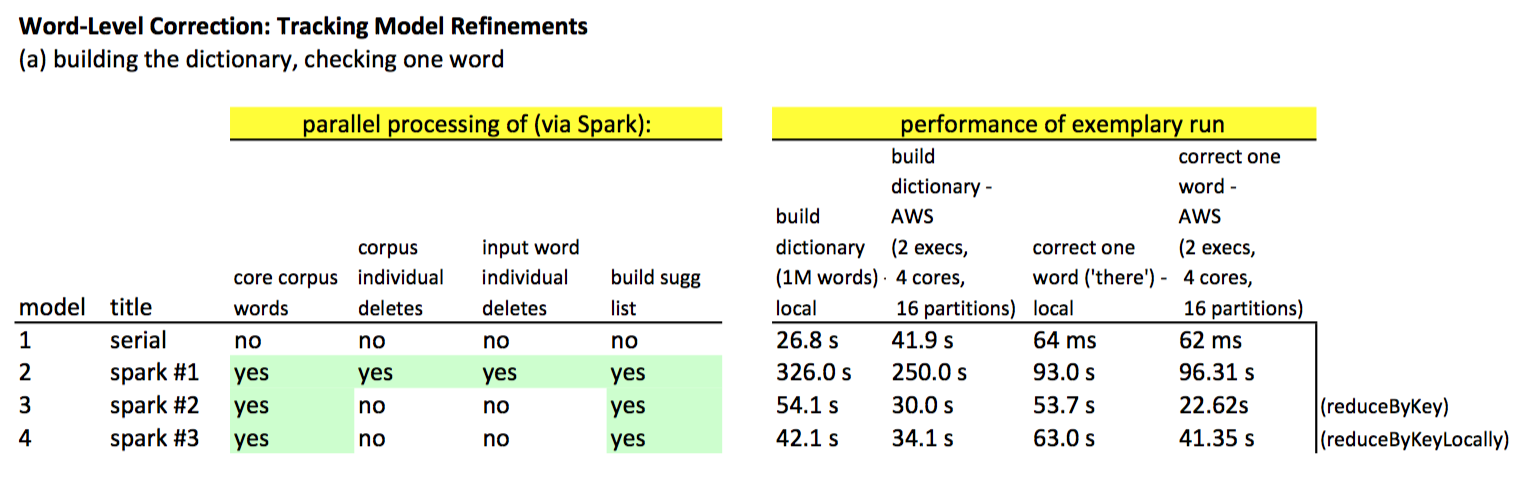 "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"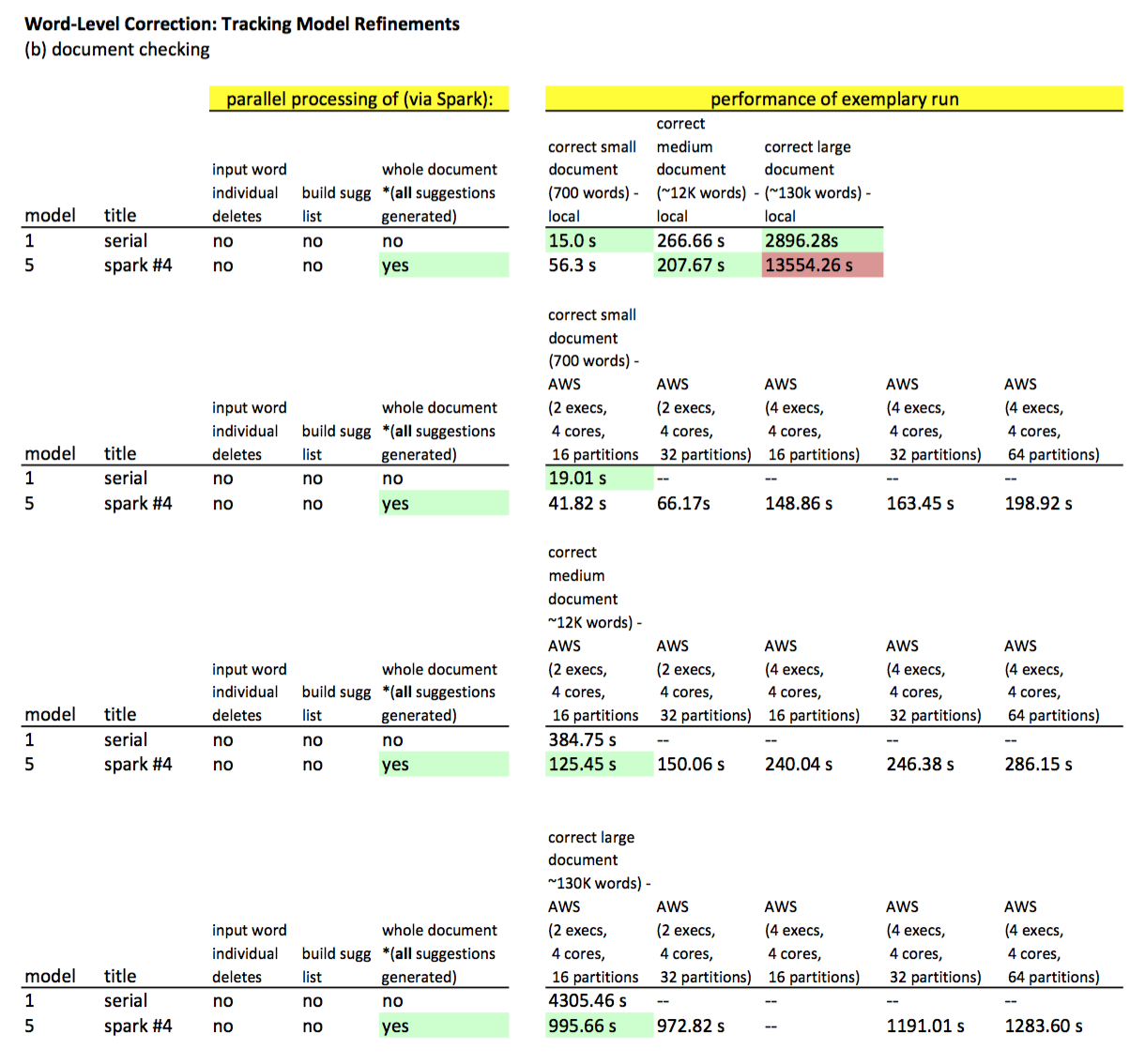 "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1a. serial code performance"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1a. serial code performance"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"